Website crawlen voor SEO: De voordelen op een rij

(Web)crawlers, ook wel spiders of spiderbots genoemd, spelen een belangrijke rol in de wereld van SEO.
Crawlers bezoeken je website en slaan de belangrijke informatie op voor later.
Hiervoor zijn zoekmachines een goed voorbeeld. Of dacht je dat Google bij elke zoekopdracht alle websites tegelijk bezoekt?
Op deze pagina lees je hoe zoekmachines je website crawlen en lees je hoe je je website kunt optimaliseren voor crawlers.
Dat niet alleen.
Ik vertel je meer over onze eigen SEO-crawler waarmee je iedere website bezoekt zoals Google en zo belangrijke informatie te verzamelen om je website beter vindbaar te maken.
Wat is een crawler?
Een crawler is geavanceerde software dat automatisch websites bezoekt. De bekendste crawler van het web is Googlebot.
Hoe een crawler werkt? Simpel.
Een crawler begint met een website-URL of een lijst aan URL's. De crawler bezoekt de pagina achter de URL en slaat de gegevens van de pagina op.
Tijdens het bezoek zoekt de crawler naast informatie ook naar links op de pagina. Deze links worden gebruikt om andere pagina's binnen dezelfde website te vinden.
De informatie wordt opgeslagen voor later gebruik.
Waarom zijn crawlers belangrijk?
Crawlers zijn belangrijk voor zoekmachines zoals Google. Zoekmachines gebruiken de informatie die crawlers verzamelen om de volgorde van de zoekresultaten te bepalen.
Als je dus op Google zoekt naar "marketing tips", dan toont Google je de websites die crawlers als relevant hebben beoordeeld.
Hoe kun je crawlers helpen?
Je kunt crawlers helpen door je website zo toegankelijk mogelijk te maken. Dat betekent dat een crawler eenvoudig bij belangrijke informatie kan komen.
Een goed gestructureerde website helpt hier bij.
Je website optimaliseren voor crawlers
Hoe efficiënt crawlers je website kunnen crawlen hangt van dan de crawl budget van je website. Grote websites met veel verkeer hebben vaak een groter crawlbudget dan relatief kleine websites.
Toch is het belangrijk voor website van ieder formaat bewust te kijken naar het crawlbudget. Worden de belangrijkste pagina's regelmatig gecrawld? En is nieuwe informatie snel zichtbaar in Google?
Er zijn vijf tactieken om de crawl efficiëntie van je website te verhogen.
1. Zorg voor snelle laadtijden
Snelle laadtijden zijn belangrijk voor een efficiënt crawlen. Je website moet in staat zijn veel pagina's in korte tijd te serveren om Google te voorzien van belangrijke informatie.
Wanneer pagina's lang nodig hebben om te laden, gaat dit ten koste van je crawlbudget.
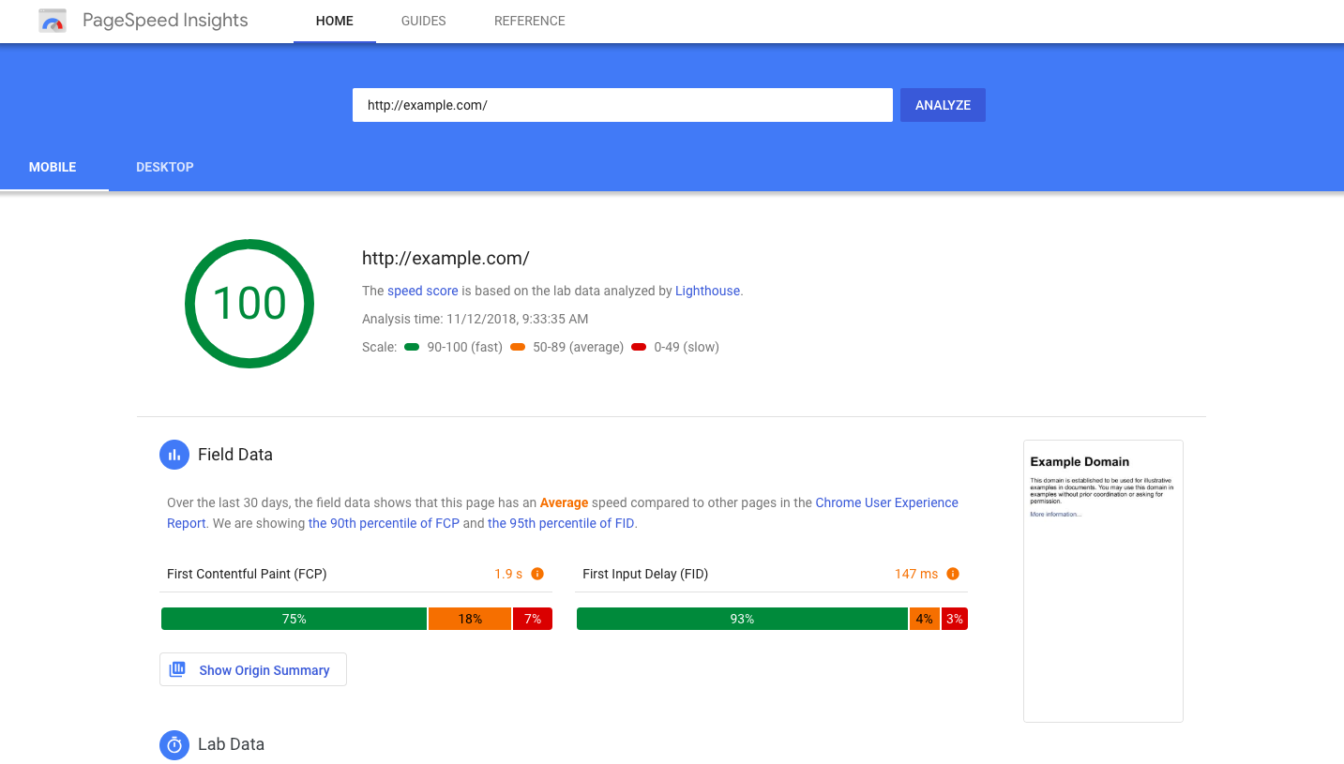
Test je website snelheid via https://pagespeed.web.dev/.
Een performance-score van minimaal 50% is gewenst.
2. Check voor crawl problemen
Er zijn twee manieren om vroegtijdig problemen op te sporen die het crawlen van je website in de weg kunnen zitten.
Een daarvan is Google Search Console.
Heb je je website nog niet bij Google Search Console aangemeld? Volg dan deze gids om je website aan te melden bij Google of bekijk hieronder de tweede mogelijkheid.
Is Search Console al actief? Open het dan via https://search.google.com/u/0/...
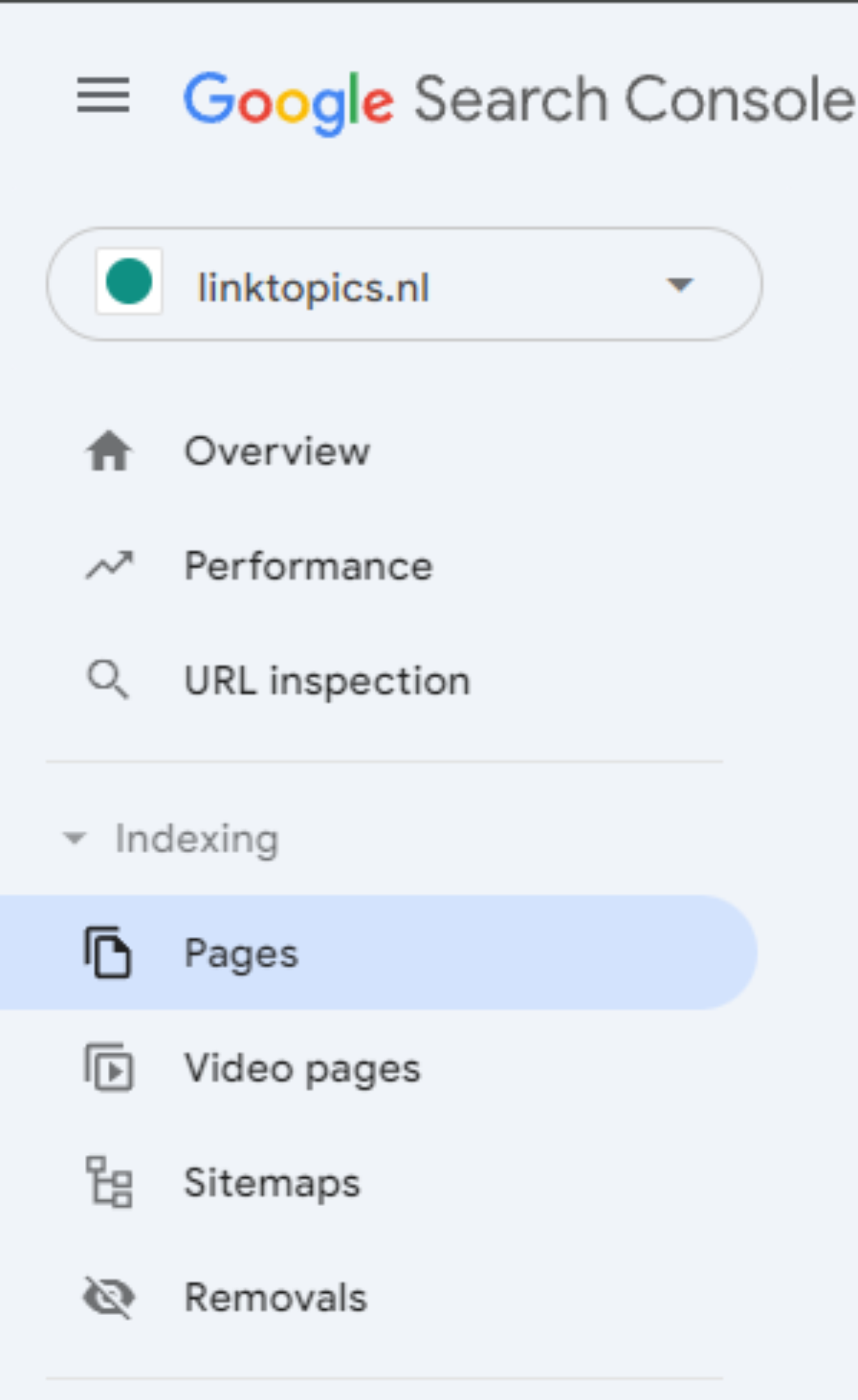
Klik na het inloggen onder Indexing op Pages:
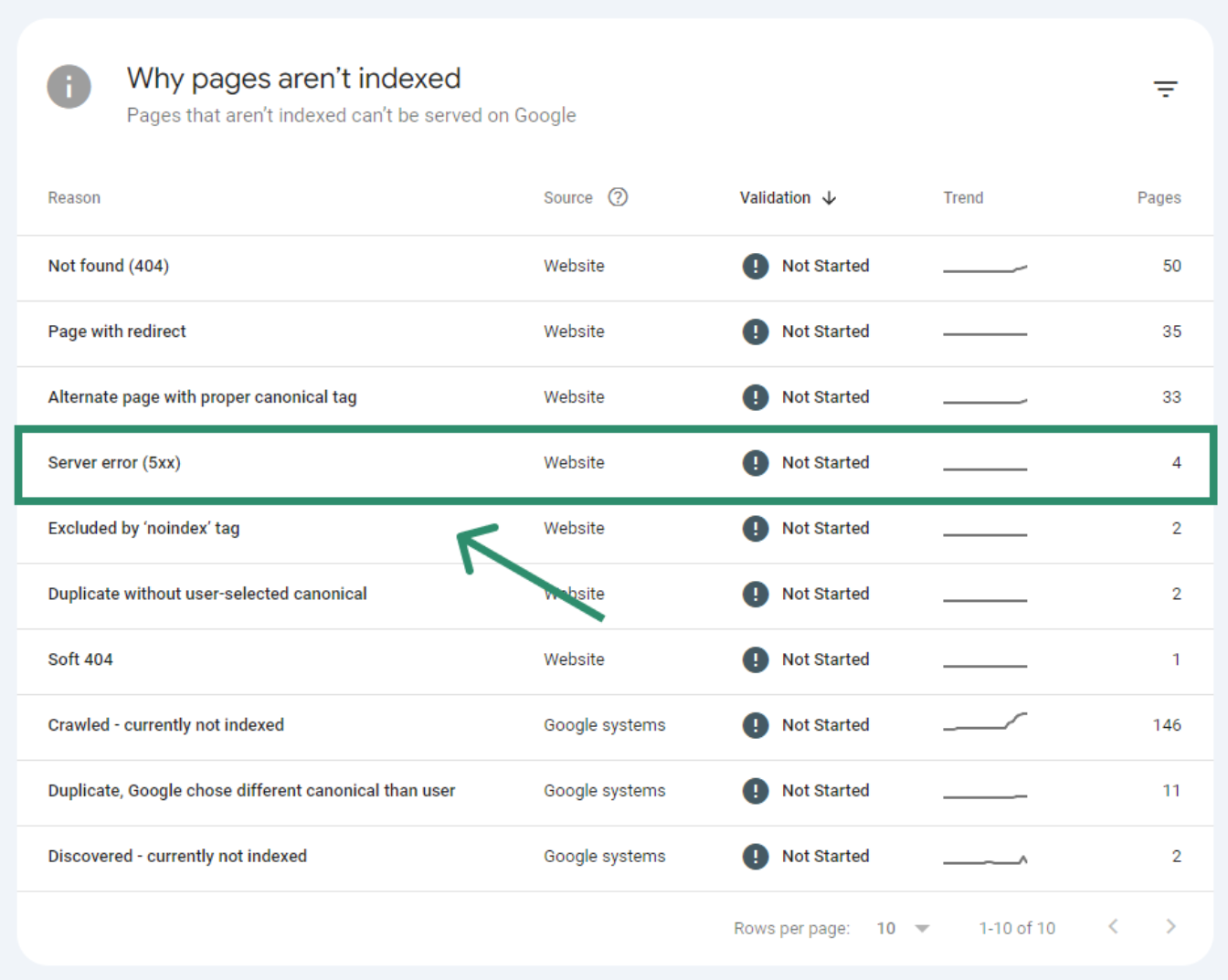
Kijk vervolgens onder "Why pages aren’t indexed".
Hier zie je mogelijke problemen die Google heeft gehad bij het crawlen van je website.
Belangrijk is dat de "Server error (5xx)"errors zo snel mogelijk worden opgelost.
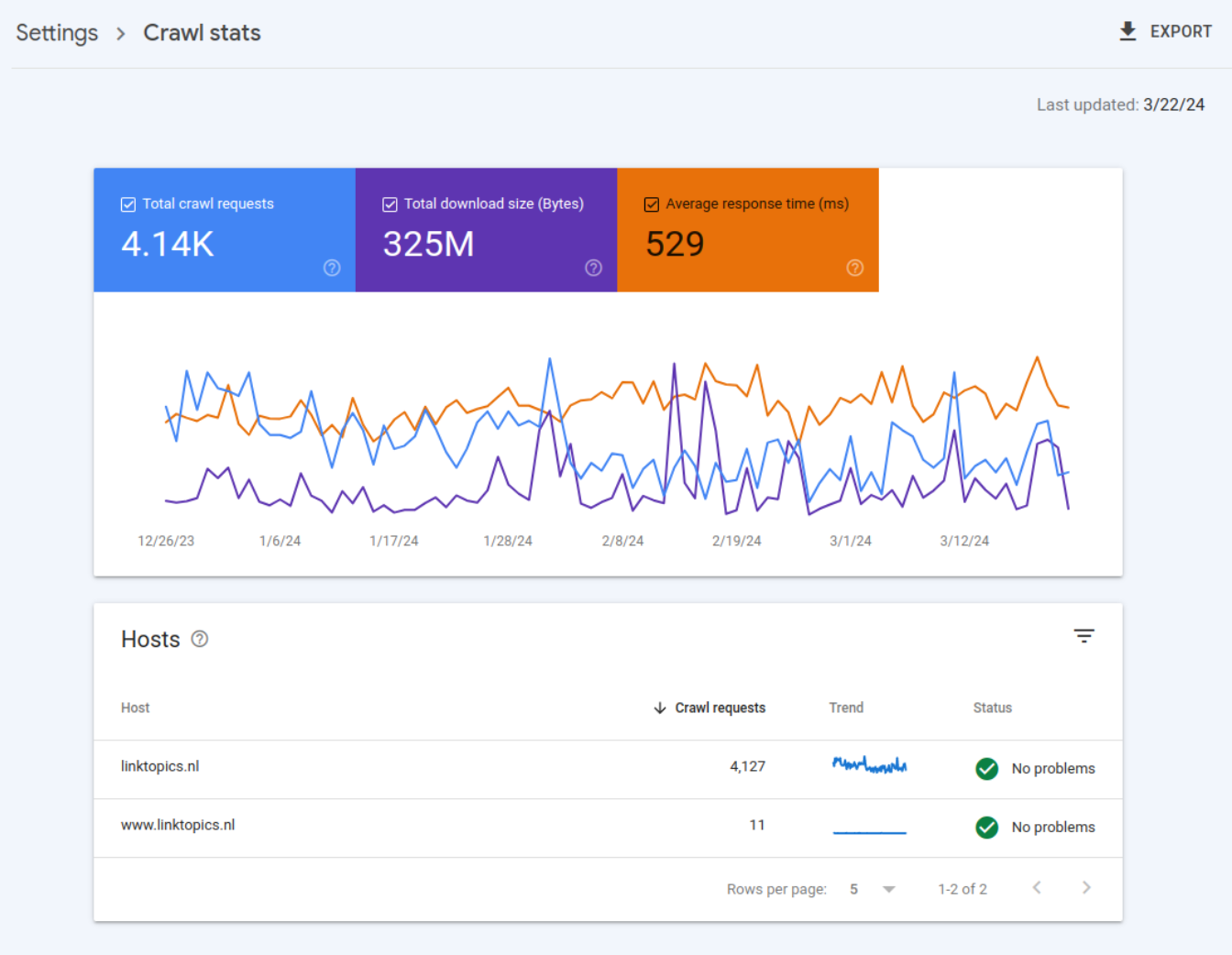
Een andere optie is om je website zelf te crawlen met tools zoals Screaming Frog of de Linktopics Website Crawler.
Open de SEO Website Crawler en vul je website-URL in.

De crawler bezoekt nu al je pagina's. Mogelijke foutmeldingen vind je in het tweede tabje onder "Foutmeldingen".
Gebruik de gratis zoekwoord tool
Boost SEO results with powerful keyword research
Gratis zoekwoord tool


Wil je hoger in Google komen?
Linktopics laat zien hoe je je website eenvoudig hoger in Google krijgt en meer verkeer naar je website krijgt.

Deze site maakt gebruik van cookies
Wij gebruiken cookies voor het bijhouden van statistieken, om jouw voorkeuren op te slaan, maar ook voor marketingdoeleinden (bijvoorbeeld het afstemmen van advertenties). Wil je je voorkeuren aanpassen, klik dan op ‘Zelf instellen’. Door op ‘Alle cookies toestaan’ te klikken, ga je akkoord met het gebruik van alle cookies zoals omschreven in onze cookieverklaring.